
Reinforcement learning (RL) is gaining a lot of popularity these days. From robotics to fine-tuning large language models (LLMs), RL is carving out a unique niche—especially in cases where traditional supervised learning doesn’t fit well. RL frameworks are inherently about control, making them ideal for robot decision-making and real-world interaction.
That said, RL has its critics—and not without reason. When the problem scales up, RL can struggle to converge due to what’s known as the curse of dimensionality. For example, if the agent’s input is an image, the state space (number of possibilities to be considered) technically includes every possible pixel configuration—an astronomical number. However, with techniques like function approximation (using neural networks), we can generalize across states and make the learning feasible.
Despite its challenges, RL is already having a positive impact in robotics and other fields, and more people are starting to talk about it.
Table of Contents
WTF is RL?
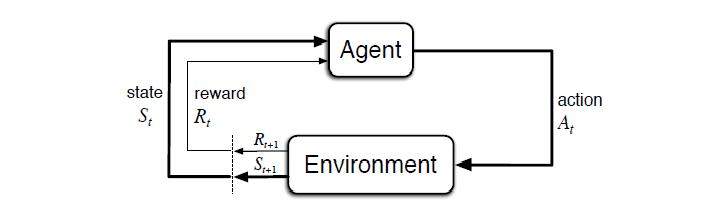
Reinforcement learning is a learning paradigm where an agent interacts with an environment and learns through trial and error. Instead of being trained on labeled data (like in supervised learning), the agent learns by receiving rewards or penalties based on its actions.
At a high level:
- The agent takes an action
- The environment responds with a new state and a reward
- The agent learns which actions lead to better long-term outcomes
Analogy: Think of training your dog to fetch. Every time it gets the ball and returns it, you give it a treat. Over time, the dog learns to fetch because it maximizes the number of treats.
State, Action, Reward and Policy
Let’s say you’re training a mobile robot to reach its charging dock. You don’t give it a map of your home, but it has cameras and sensors to observe its surroundings. This is a great use case for RL.
Here’s how it breaks down:
State – The robot’s current position and sensor readings
Agent – The robot
Environment – Your home
Actions – Move forward, backward, left, right (or control each wheel’s speed)
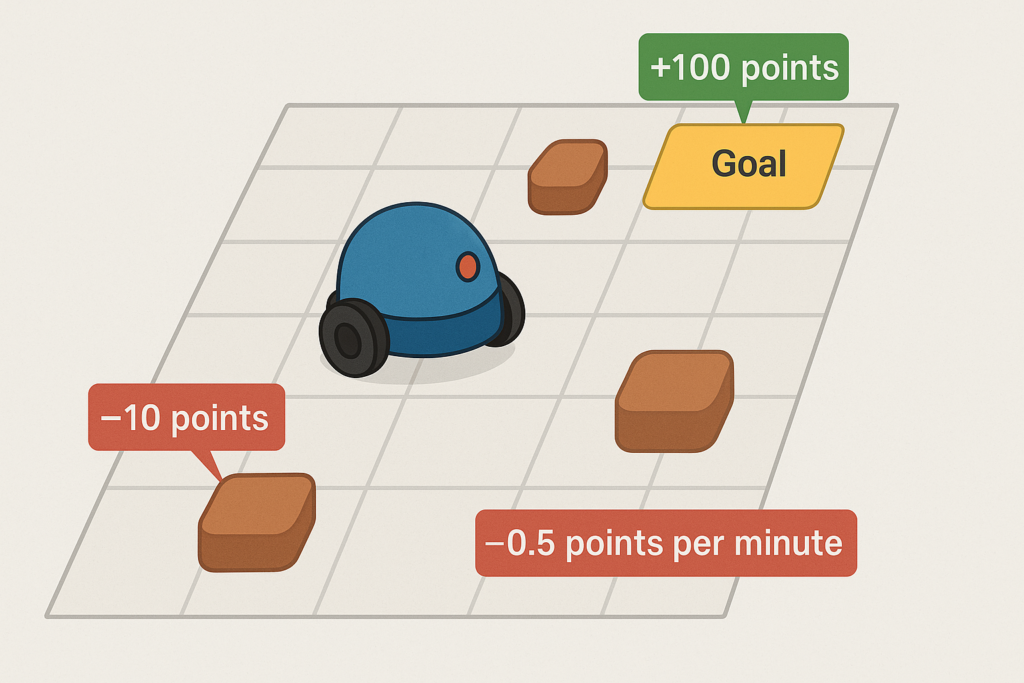
Reward Function Example:
- +100 for reaching the goal
- –10 if it bumps into an obstacle
- –0.1 per time step (to encourage faster solutions)
- –50 if it exceeds a time limit (e.g., 5 minutes) → episode ends
This reward function basically says: reach the goal as efficiently as possible without crashing into things.
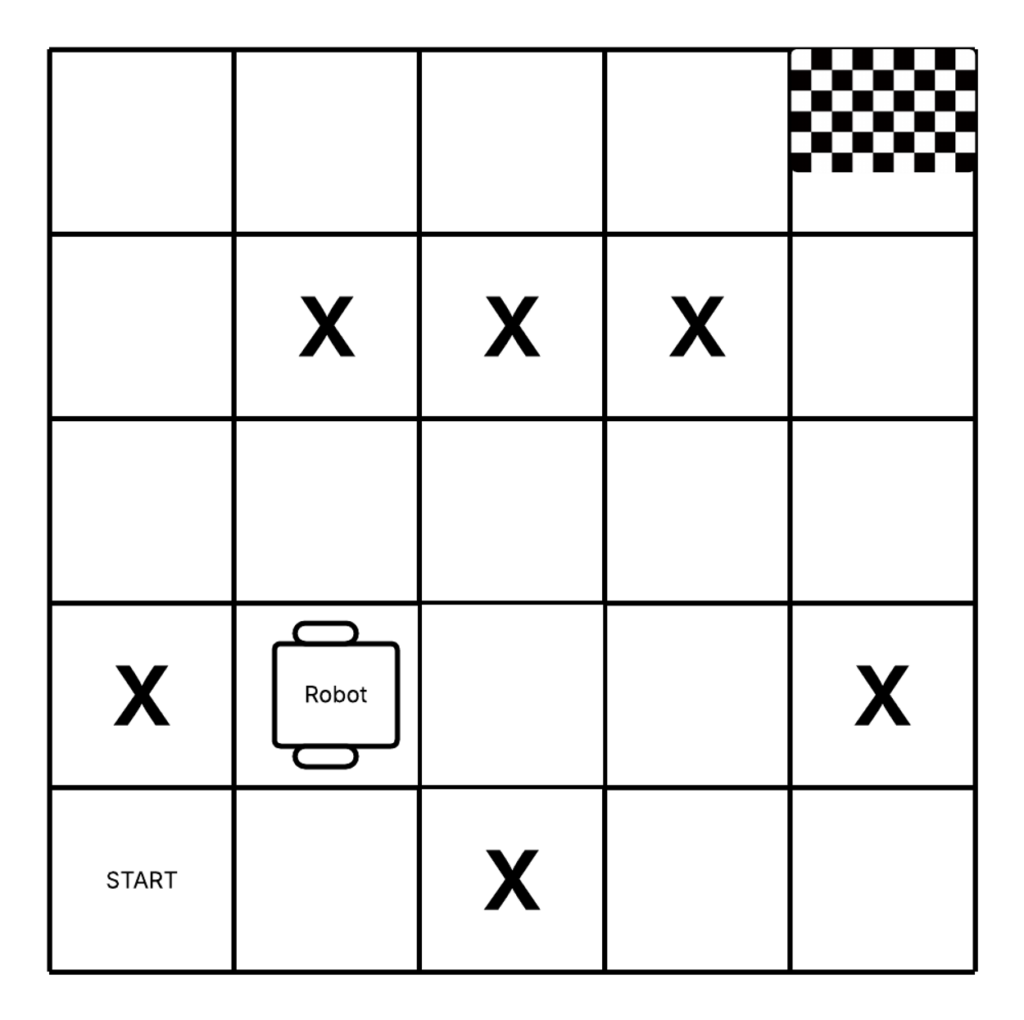
Imagine the environment is split into 25 tiles. The top-right tile is the goal, and some tiles have obstacles marked with X. The robot starts in a random location. At first, it takes random actions, like so:
P(move_foreward) = P(move_backward) = P(move_right) = P(move_left) = 0.25
This is called a uniform random policy, which is commonly used to initialize training. Over time, the agent should learn a better policy π(a|s)—a function that tells it what action to take in any given state.
- A deterministic policy picks the same action every time for a given state (other actions’ probability is 0)
- A stochastic policy picks an action based on a probability distribution
The goal of RL is to learn an optimal policy that maps each state to the best possible action(s) to maximize cumulative reward.
Exploration and Exploitation
As the agent learns a policy, you might think it should always take the most rewarding action at each step. But that can lead to suboptimal behavior, especially if the agent hasn’t explored certain paths.
Let’s go back to our robot. Say it lands in tile (3, 5) and reaches the goal by taking a roundabout 10-step path. Why not the shortcut?
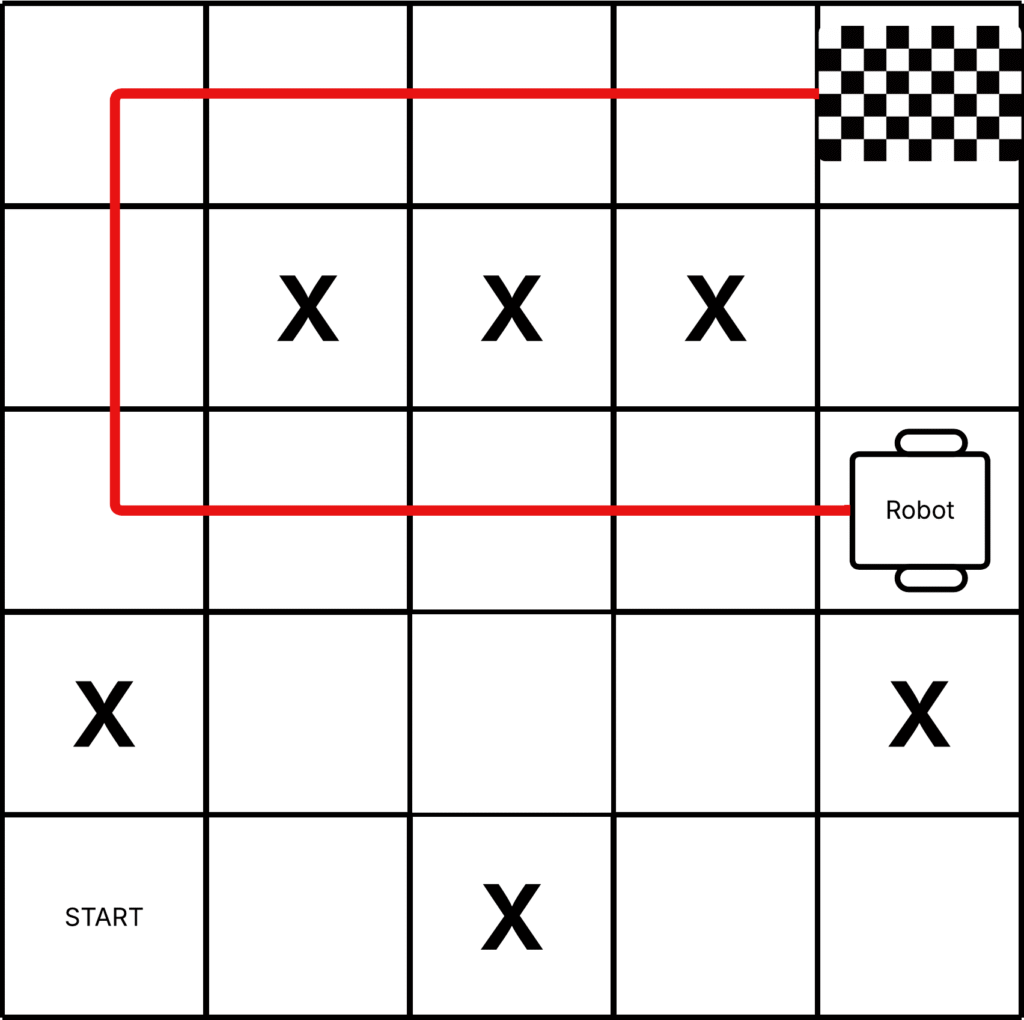
Maybe during training, the agent never explored tile (4, 5) because it assumed it was surrounded by walls or obstacles—or it just never got there randomly. Since it hadn’t seen that state before and was acting greedily, it ignored potentially better options.
This is why we need a balance between:
- Exploration – Trying new actions to discover their potential
- Exploitation – Choosing known high-reward actions
One common strategy is ε-greedy:
With probability ε (say, 0.1), take a random action (explore),
With probability 1–ε, take the best known action (exploit).
Over time, as the agent gains experience, ε is decayed to encourage more exploitation while preserving occasional exploration.
The knowledge it builds up during exploration is captured in functions like:
- Vπ(s) – Value of being in state s under policy π
- Qπ(s, a) – Value of taking action a in state s under policy π
Don’t worry if this seems abstract—we’ll cover it soon.
🤖 Had our agent been encouraged to explore more, it might have discovered the shortcut path earlier and saved battery life while reaching the dock faster.
Training’s not done yet – more episodes coming up. Stay tuned!